


Software: Python

This project, completed as part of the course DS4300: Large Scale Information Storage and Retrieval, is a Retrieval-Augmented Generation (RAG) system built on course notes. My teammate and I tested different variables to determine the most effective combination of chunking strategies, embedding models, prompt engineering, LLM, and vector database options. Ultimately, through evaluating statistics and results from the tested combinations, we found the most effective pipeline to be as follows:
Chunking: 1000 tokens Overlap: 0 tokens Embedding: all-minilm-l6-v2
Prompt: “you are a professor explaining concepts to a student”
Vector database: chroma
LLM: llama3.2
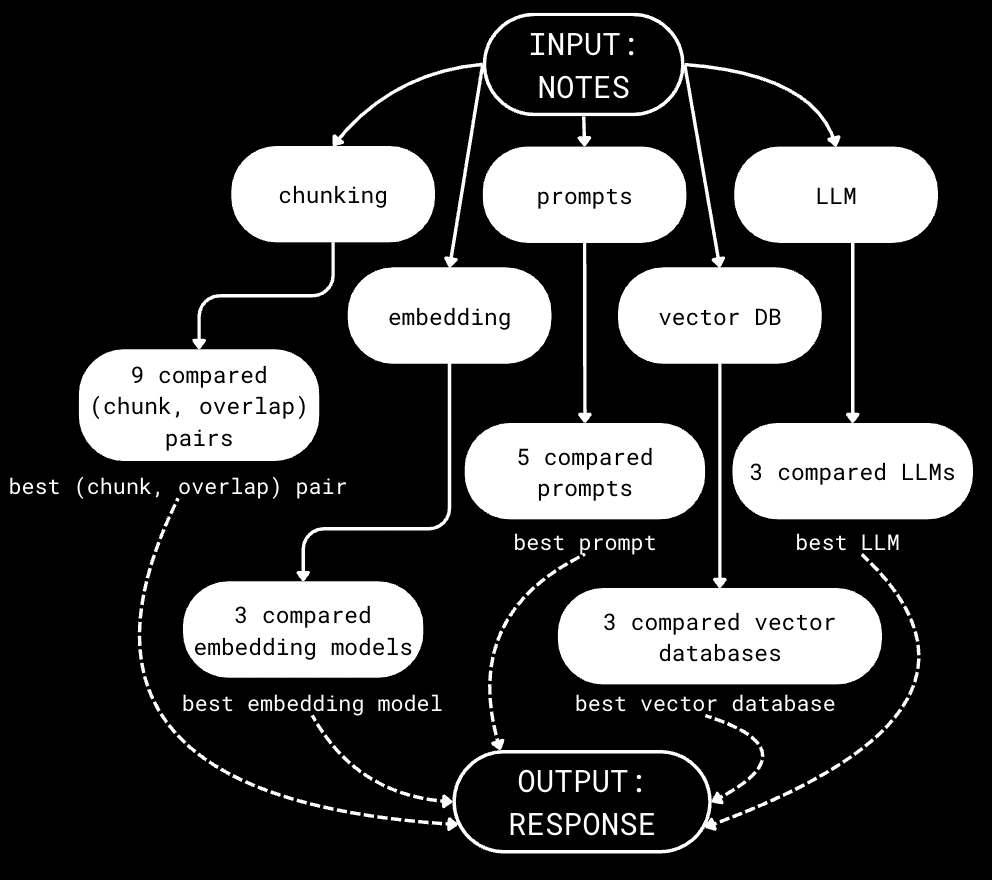
Workflow diagram

Redis
Use RedisStack via Docker Desktop
Cloud or local deployment
Built database for retrieval
In-memory/local storage
Scalable
Generally low overhead
2. ChromaDB
Use Ollama and create a collection
Runs on server
Built database for retrieval
Local storage
Potentially scalable
Low overhead
Store embeddings, documents, & metadata
Index vectors
Vector search
Update vectors & metadata
Delete and cleanup
3. MongoDB + Atlas
Use Atlas Cluster + Vector Search Index + Compass
Cloud service/storage
Vector search over existing databases
Potentially scalable
High overhead

Embedding models are used to transform data, in this case course notes, into vectors for comparison.




Data processing diagram

Mistral:latest
Developer: Mistral AI
Parameters: 7.3 billion
MMLU score (5-shot): 60.1%
GSM8L score (8-shot, CoT): 13.2%
2. Gemma3:1b
Developer: Google Gemma Team
Parameters: 1 billion
MMLU score (5-shot): 38.8%
GSM8L score (8-shot, CoT): 62.8%
3. Llama3.2
Developer: Meta
Parameters: 1.26 billion
MMLU score (5-shot): 49.3%
GSM8L score (8-shot, CoT): 44.4%
Key Takeaways:
Mistral has the highest MMLU score, meaning that it has stronger knowledge and reasoning than Llama3.2 and Gemma3:1B.
Llama 3.2 1B has highest GSM8K score, indicating it has the highest mathematical problem solving skills of the three LLMs.

To find the optimal chunking strategy, we pre-defined nine different combinations of chunking size and chunking overlap in our ingest.py script used to ingest documents
This included three different chunk sizes (200, 500, 1000 tokens) and three different chunk overlap sizes (0, 50, 100 tokens):

We then used a “for” loop in our main() function to loop through each chunk size and overlap size
To compare only the effect of varying chunk size and overlap size, we kept the vector database and embedding type constant across experiments (Redis and nomic-embed-text, respectively) and ran all strategies on the same query: “What is a binary search tree?”
To test the remaining variables, we developed five user questions we fed to various versions of our pipeline:
What are the trade-offs between using a contiguously allocated list and a linked list for storing a collection of elements?
Give an example of a situation where a doubly linked list is more efficient than a singly linked list. Why?
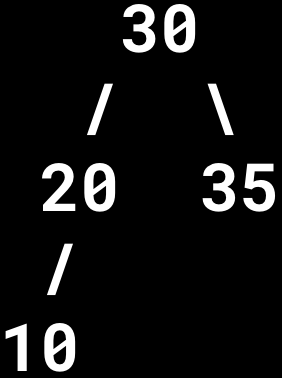
Insert 40 into the following AVL tree:
What rotations (if any) are needed to maintain balance? How might this insertion/rebalancing differ with a Binary Search Tree or B+ tree?
4. What does the `$regex` operator do in a MongoDB query? Provide an example.
5. Write a sample code function to perform a Binary Search.
Instead of running all the different versions of our LLM, embedding type, vector database, and system prompt for all five user questions, we only modified one variable for each question to observe which model performed the best. After identifying the model that performed best for the given variable (ex: mistral:latest for LLM), we used that model for the remainder of the user questions.
This allowed us to test a singular variable with each question and refine our optimal pipeline to a single LLM, embedding type, vector database, and system prompt. The variable testing per question was as follows:


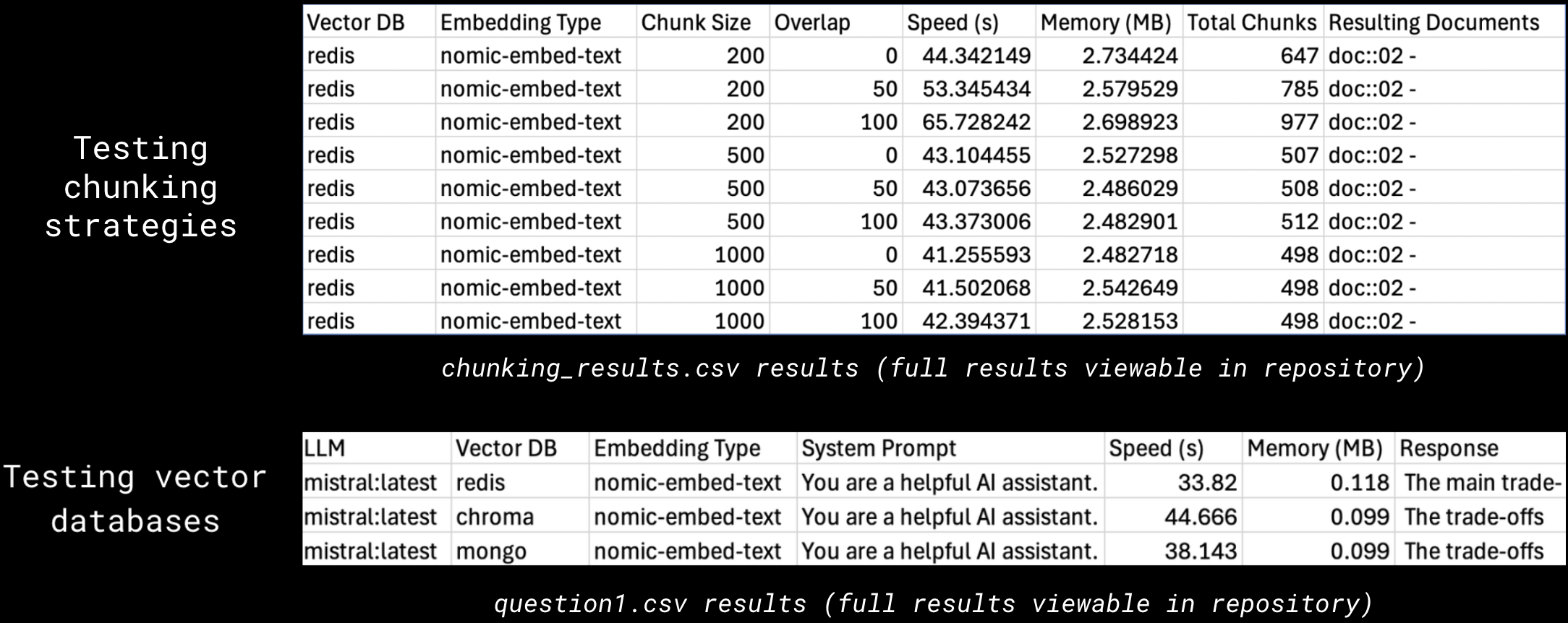
The testing results of each chunking strategy was stored in a .csv file (chunking_results.csv)
The .csv file contains the following information for each experiment:

The resulting documents column represents the documents the given chunking strategy returned for the testing query, “What is a binary search tree?”
The testing results for each user question was stored in a .csv file (question1.csv, question2.csv, question3.csv, question4.csv, question5.csv)
Each .csv file contains the following information for each experiment:

In this case, the query posed to the system was one of the five user questions we developed



Of the variables collected in chunking_strategies.csv, only Speed (in seconds), Memory (in MB), Total Chunks and Resulting Documents would be potentially relevant in identifying the optimal chunking strategy (Vector DB and Embedding Type were held constant)
Total Chunks did not prove to have a significant impact on the resulting documents returned; in fact, the Resulting Documents proved to be the same across chunking strategies, with the exception of the last document in the list in some cases (KNN was set to 5, so five documents were returned)
Therefore, we found that the most relevant factors to consider when determining an optimal chunking strategy were Speed and Memory, which we used to make our ultimate chunking strategy recommendation
To determine which LLM/vector database/embedding type/system prompt was best, we evaluated each pipeline’s response to the given user question using five criteria, giving a score out of five for each:

We chose these specific criteria because they consider both factual correctness and usability, factors we believed to be most important for the end user’s use case (using a RAG-based system on a timed course exam)
We also believe these criteria are specific enough to extract slight differences in pipeline performance (ex: multiple versions can be accurate, but fewer go into sufficient depth)
Using this evaluation system, the results were as follows…




For a team of similar size wanting to create a RAG-based system for using on an exam, we recommend the following pipeline based on our extensive evaluation criteria scores:
Chunking Strategy: Chunk size: 1000 tokens, Overlap: 0 tokens
Selected as the optimal strategy due to being the fastest approach while also having the smallest storage footprint
Embedding Model: all-MiniLM-L6-v2
Gave more relevant results than nomic-embed-text and all-mpnet-base-v2, ensuring the system pulls the most useful study material for queries
System Prompt: "You are a professor explaining concepts to a student."
More effective than generic AI assistant or technical writing prompts by ensuring responses are structured for clarity, depth, and student comprehension
Vector Database: Chroma
Performed better than Redis and Mongo in retrieving relevant information quickly and accurately, making it ideal for efficiently searching through study materials
LLM: Llama3.2
Chosen over Mistral:latest and Gemma3:1b for its balance of accuracy, reasoning capabilities, and efficiency in handling complex academic queries
By using this pipeline, we believe the team’s RAG system will be optimized for information accuracy and retrieval on exam day.

This project encouraged me to think about the use case of the code I was writing and consider the ways in which our program would be most user-friendly. To do this, my teammate and I spent a lot of time building tests and criteria that comprehensively evaluated every possible scenario for optimal performance on test day using our final RAG pipeline. As a result, I left the project feeling as though I better understood the fundamentals behind a successful RAG interface and how the choice of chunking strategy, embedding model, system prompt, vector database, and LLM can affect the final outcome.
After ingesting all of my course notes and using our recommended RAG pipeline, I earned a 97.5% on the midterm exam for this course with minimal additional studying, showing how our RAG interface and recommendation were well-structured. Getting to use our RAG interface on our course exam made this project more exciting, and I am grateful to have learned more about LLMS and chatbots through this experience due to their increasing relevance in tech.